Our Journey with Headless CMS
Contents
Content management systems (CMS) have been affected by huge changes in recent years — among them is the emergence of headless CMS tools. We recently decided to use headless CMS for a new feature of our internal app, and after looking at the many options, we landed on Strapi. This blog post will outline what headless CMS is, why we chose it, what led us to Strapi, and how we use it.
Who Is This Blog Post For?
Is this your first time using headless CMS, or do you already have experience? To be honest, it doesn’t matter. If you’re looking for a headless CMS solution, and if you’re considering using Strapi, this post is a good starting point for you. However, even if you haven’t decided on Strapi or you’re not sure which solution you’ll opt for, we hope it still provides some insight on headless CMS.
Headless CMS
A content management system is software that allows users to create and manage a website’s contents. Meanwhile, headless CMS is a backend-only version. According to an article in The American Genius by Veronica Garcia, “It decouples where your content is stored and authored (body) from the front-end where your content is displayed (head).” This allows you to make content accessible via an API without the need for a built-in frontend.

But, what is headless CMS in practice? Let’s dive into it!
Typically, there are two layers in a traditional CMS: the content and the presentation layer. Contrary to this, a headless CMS contains the content component only and is based on the admin interface for creating, editing, and organizing content. Headless CMS is not connected to presentation layers, templates, site structure, or design. Instead, created content is stored in a “raw” format, and it provides access to other components by means of stateless or loosely coupled APIs.
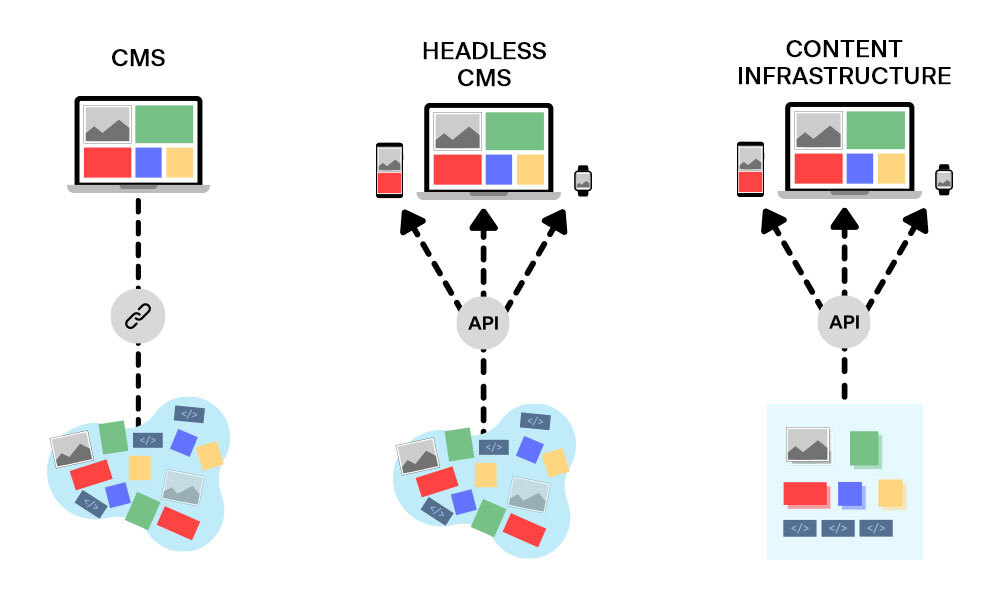
So, to recap the differences:
- Traditional CMS — puts all the data in one big bucket; reusability is impossible
- Headless CMS — allows choosing the presentation layer; doesn’t structure the data, so the data can be reused
- Content Infrastructure — a type of headless CMS, but it doesn’t organize content by pages
Why We Opted for Headless CMS
For our internal platform, we created a new feature known as Toolbox. Toolbox is a repository of different methods and tools along the 3AP value chain, and it enables the people at 3AP to understand which method, set of methods, tools, and best practices can be applied to a specific use case in daily work. And naturally, headless CMS provides the data for our new feature, because it lets us choose our presentation layer, reuse our data, and easily create and manage content.
Main Requirements for a 3AP Headless CMS Solution
Once we decided to use a headless CMS solution, the next step was to choose the right one. There are many competent solutions on the market, so we began by outlining our main requirements:
- Friendly non-technical editor
- User and access management
- Content types and taxonomy
- Content staging workflows (draft/review/published)
- Versioning
- Asset library
After a lot of research, we ended up with Strapi. 🎉
Strapi fulfilled most of our requirements, and one thing that was the most important thing for us is that Strapi’s roadmap is fantastic.
We don’t want to burden readers with a lot of text detailing what went into our research, but if you’re interested in knowing more, feel free to contact us, and we’d be happy to share it with you.
Get to Know Strapi
Strapi is a free and open-source headless CMS that delivers your content anywhere you need. It’s self-hosted, it provides REST and GraphQL APIs, and it’s written completely in JavaScript. It also has a fast, user friendly, and customizable admin panel, which helps in saving development time.
For more information, refer to the Strapi website. We also recommend you check out the Strapi documentation and Strapi Academy, the latter of which can be helpful for beginners.
What Are the Advantages of Strapi for Our Business Case?
Strapi has a lot of great features, and below is a list of some of the selling points (for us):
- Relatively quick project setup and deployment
- Easy collection types creation
- Easy content management
- Numerous useful plugins:
- Easy roles and permissions setup
- Customization
- A draft and publish system
Our Business Requirements
We had to provide a solution for 3AP employees to enable them to understand which tools or best practices (methods) can be applied to the different use cases in our daily work. Then, we had to provide basic requirements such as:
- CRUD operations
- Searching
- Filtering
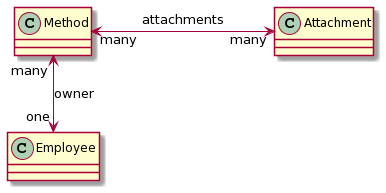
- Attachments
- A draft-publish-archive content workflow
All of the above requirements were attainable through our headless CMS solution.
The simplified class diagram below shows the supported Strapi collection types.
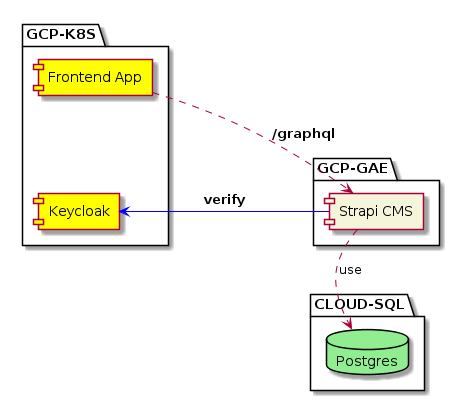
Architecture
Here is a list of the architecture required to integrate Strapi into our app:
- GCP-K8S — hosts the IDP Keycloak and frontend app
- CLOUD-SQL — hosts Strapi’s Postgres database
- GCP-GAE — hosts the Strapi app
Integration with Keycloak
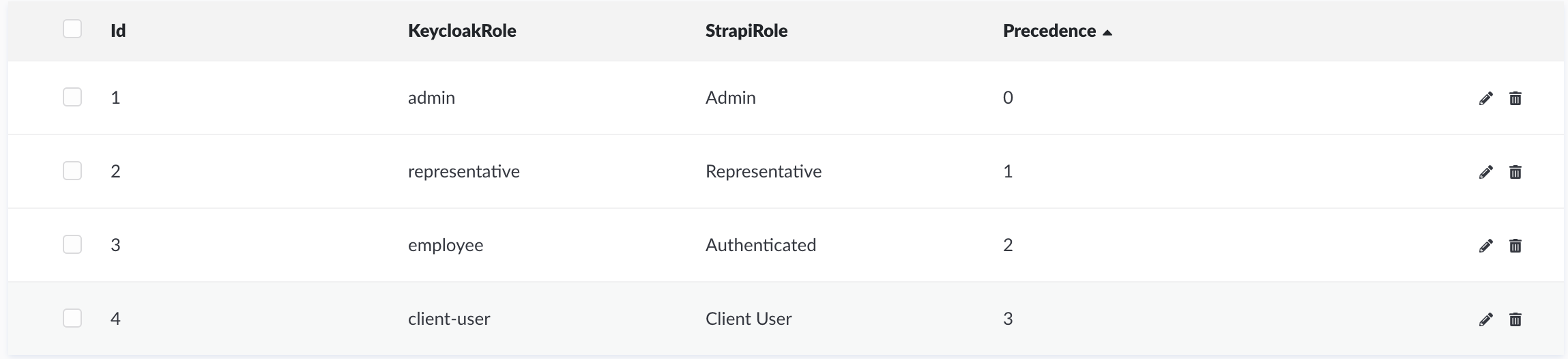
An identity provider (IDP) is in charge of storing and managing digital identity information. It also provides authentication services. In our app, we use Keycloak IDP, which provides us with user roles. For the purpose of the Toolbox feature, we used four roles (respectively, from lowest to highest privileges):
- client-user
- employee
- representative
- admin
We integrated Strapi with Keycloak using a custom permissions module that parses the Keycloak JSON Web Token (JWT) and adds a respective Strapi role. This resulted in the creation of a new collection type called keycloak-mapping, which is in charge of defining mapping Keycloak roles to Strapi roles. Additionally, it’s only visible to the Strapi Dashboard role of a Super Admin. Based on the Keycloak roles, a Strapi role with the highest precedence (lower number) will be set.
In other words, the client must provide a valid JWT issued by Keycloak on behalf of the user. Strapi will verify the JWT against Keycloak, identify the roles provided by Keycloak, and set the appropriate Strapi role based on the highest order of precedence.
The diagram below illustrates what a single request process looks like.
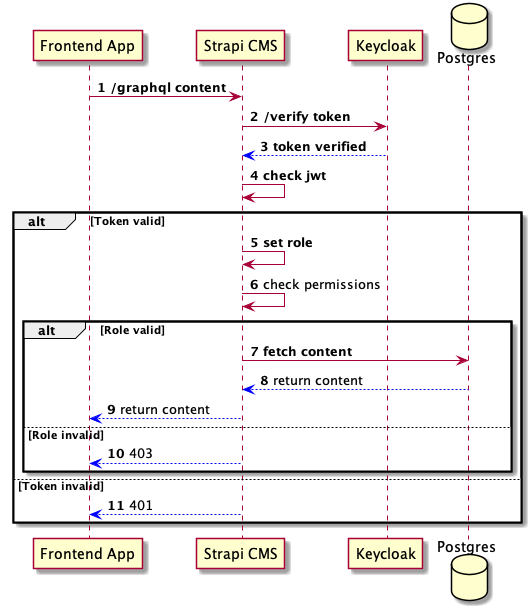
The following explains what is depicted in the diagram above:
- The client requests a resource/content via a GraphQL request with the Keycloak-issued JWT.
- A custom part of the existing access management on the CMS level verifies the JWT against Keycloak.
- Keycloak returns the result of the verification of the JWT.
- If the client provided an invalid JWT, it proceeds to 11.
- The CMS parses the JWT, checks the provided Keycloak roles, and sets the appropriate user role based on the highest precedence.
- The CMS checks if the client has the required user role to access the resource, and it proceeds to 10 if not.
- The requested resource is queried from the database.
- The database returns the queried result.
- The resulting content is returned to the client.
- The CMS returns a 403 because the client tried to access a resource for which it doesn’t have the appropriate role that can be matched in Strapi.
- The CMS returns a 401 because the client provided an invalid JWT.
Draft — Publish — Archive
Strapi is supported by a feature known as Draft and Publish, which is passed on two important parameters:
publicationStateis a method parameter.published_atis an attribute found on the table level of all collection types and can be retrieved with a query or mutation.
In the following table, you can see how the status of the method depends on these two parameters:
publicationState | published_at | Status |
|---|---|---|
| LIVE | != null | Published |
| LIVE | == null | X |
| PREVIEW | != null | Published |
| PREVIEW | == null | Draft |
The following diagram explains method states: We extended them with a new field, Active, which is located inside the collection type.
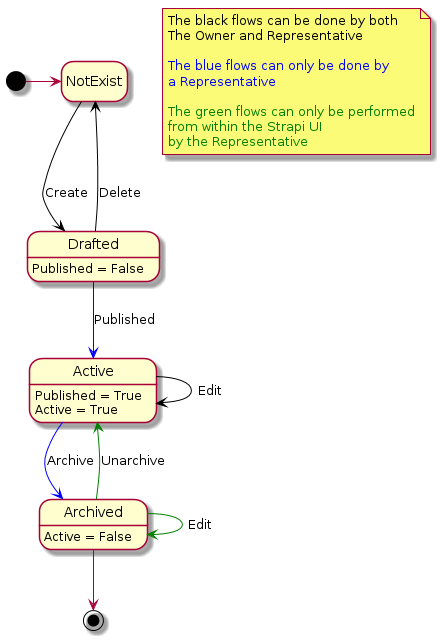
From the diagram above, we can conclude that there are three states of the method: drafted, active, and archived. The drafted method is represented by the out-of-the box draft-publish system parameter Published = False. The active method has to fulfill both Published = True and our custom field, Active = True. For the archived methods, only Active = False is checked.
Attachments
One of our requirements was to provide a solution where users can upload files and images to the method as attachments. For that purpose, we used the Strapi File Upload plugin. It makes the job much easier, so in just few steps, everything was set up.
By default, Strapi has a provider that uploads files to a local directory. We wanted to upload files to Google Cloud Storage, so we needed a different provider. We decided to use Strapi Provider Upload Google Cloud Storage, but if you want to see the other providers available, you can check out the Strapi Providers Collection.
We added the following, which is a Google Cloud Storage provider example with environment variables, to the ./config/plugins.js file:
upload: env('GCLOUD_STORAGE_UPLOAD_ENABLED') === 'true' && {
provider: 'google-cloud-storage',
providerOptions: {
baseUrl: env('GCLOUD_BASE_URL'),
bucketName: env('GCLOUD_BUCKET_NAME'),
serviceAccount: env('GCLOUD_SERVICE_ACCOUNT_KEY'),
publicFiles: true,
uniform: false,
basePath: '',
},
},
Custom API
Strapi provides a powerful out-of-the-box GraphQL API that’s auto-generated with each collection type added. However, for the purposes of our project, we also implemented custom routes.
The frontend app consumes a custom API that implements the behavior driven by the project requirements.
The contract follows the AND behavior, meaning all criteria entered by the user must be matched to return the result, if any. The result always contains the Active and Published methods, and Archived or Draft methods are not covered by the search and filter use case described in the following section. Furthermore, the methods will always be ordered by the name ascending, and text matching will be done in a case-insensitive manner.
The first query, Toolbox, is our custom query, and it returns the method filtered by the forwarded options. It checks for the parameters and filter methods first, and then it inspects the role of the user who requested the data. Based on the role, different data is returned:
Query: {
toolbox: {
description: 'Returns methods filtered different parameters',
resolverOf: 'application::method.method.toolbox',
resolver: async (obj, options, {context}) => {
const {principal, role, employee} = context.state.user;
let { /* query options */ } = options;
//...
// prepare query options as query arguments
//...
const params = {
_where: {
...(active === false ? {active: false} : {active: true})
},
_sort: 'name:asc',
_publicationState: 'preview'
};
try {
const toolboxContent = await strapi.services.method.find(params);
const draftMethods = [];
const publishedMethods = [];
const isRepresentative =
role.type === 'representative' ||
role.type === 'admin';
const isEmployee = (method) =>
role.type === "authenticated" &&
method.owner.googleId === employee.googleId;
methodsByCategory.forEach(method => {
if (method.published_at !== null) {
publishedMethods.push(method);
} else {
if (isMethodologyRepresentative || isOwner(method)) {
draftMethods.push(method);
}
}
});
return [...draftMethods, ...publishedMethods]
.filter(
//...
// filter by query arguments
//...
);
} catch (err) {
return null;
}
}
}
To enable a newly created route, we should update controllers inside the collection type. To do that, we add the following code:
module.exports = {
async toolbox(ctx) {}
};
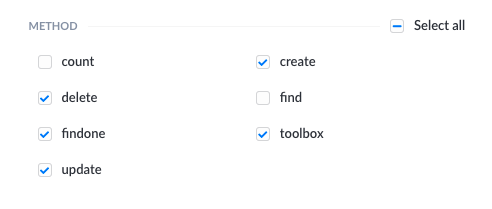
Then, the created query will be shown in the Roles & Permissions plugin, inside the Permissions field. It should be enabled.
The following query overrides the default method query, which is only extended with role checking:
Query:
content: {
description: 'Returns content filtered by id',
resolverOf: 'application::content.content.findOne',
resolver: async (obj, options, {context}) => {
const {principal, role, employee} = context.state.user;
let {id} = options;
const params = {id, _publicationState: 'preview'};
if (content.published_at !== null) {
return content;
}
//...
// special permissions check
//...
throw new Error("403")
}
}
}
Categories of a method are defined as Boolean values, and each one can be filtered by checking if its value is set to true. The following categories exist on the Method model: leanUX, salesEngagement, ventureExperience, agileDelivery, facilitation. These categories will be hardcoded on the client.
What do we expect as a result?
Categories — The result will contain a method or methods, if any, which are in the selected category. If there’s no selected category, all the methods will be sent.
Name — The user can enter a part of the method name or the exact method name, and more than one method name entry can be added in the search bar. The result will contain a method or methods, if any, which must contain all name entries anywhere in the method name.
Owner Name — The user can enter a part of the method owner name; whether it’s part of the first or last name isn’t important. They can also add more than one method owner name. The result will contain a method or methods, if any, which must contain all owner name entries anywhere in the method owner’s full name.
Tags — The user can enter a part of the tag name or the exact tag name, or more than one name. The result will contain a method or methods, if any. It must have all the name entries of the tags anywhere in the method’s tags’ names.
The following query returns methods where:
- The name contains the text “design thinking”
- The method owner’s full name contains the text “doe” and “john”
- The method tags contain the text “design” and “remote”
query {
toolbox(
names: ["design thinking"]
owners: ["doe", "john"]
tags: ["design", "remote"]
) {
name
methodTags {
name
}
description
leanUX
salesEngagement
ventureExperience
agileDelivery
facilitation
aaapStandard
}
}
Here’s an example of a method that matches the query:
| Attributes | Value |
|---|---|
| Method name | Design thinking vol.2 |
| Method owner full name | John Doe |
| Method tags | #design #remote-friendly #prototype |
And here’s an example of a method that doesn’t match the query (this one doesn’t match since it’s missing a tag with the text “remote”):
| Attributes | Value |
|---|---|
| Method name | Design thinking vol.3 |
| Method owner full name | John Doe |
| Method tags | #design #prototype |
And to Conclude
At the beginning of the post, we described who this blog post is for. Now that we’ve outlined what Strapi offers and how it works for us, we’d be interested in knowing if it’s a viable solution for you.
Generally, our journey with Strapi was really cool. But of course, there are always cons. In this case, the documentation could be more thorough by including more examples and information. However, there’s a great community that’s ready to help all the time. We haven’t found any burning issue, we haven’t had any breaking problems, and we’re going to use Strapi in our future projects for sure!